iToF-flow-based High Frame Rate Depth Imaging
CVPR 2024
Yu Meng, Zhou Xue, Xu Chang, Xuemei Hu, Tao Yue
School of Electronic Science and Engineering, Nanjing University

|
iToF-flow-based High Frame Rate Depth Imaging CVPR 2024 Yu Meng, Zhou Xue, Xu Chang, Xuemei Hu, Tao Yue School of Electronic Science and Engineering, Nanjing University
|
|
Abstract iToF is a prevalent, cost-effective technology for 3D perception. While its reliance on multi-measurement commonly leads to reduced performance in dynamic environments. Based on the analysis of the physical iToF imaging process, we propose the iToF flow, composed of cross-mode transformation and uni-mode photometric correction, to model the variation of measurements caused by different measurement modes and 3D motion, respectively. We propose a local linear transform (LLT) based cross-mode transfer module (LCTM) for mode-varying and pixel shift compensation of cross-mode flow, and uni-mode photometric correct module (UPCM) for estimating the depth-wise motion caused photometric residual of uni-mode flow. The iToF flow-based depth extraction network is proposed which could facilitate the estimation of the 4-phase measurements at each individual time for high framerate and accurate depth estimation. Extensive experiments, including both simulation and real-world experiments, are conducted to demonstrate the effectiveness of the proposed methods. Compared with the SOTA method, our approach reduces the computation time by 75% while improving the performance by 38%. |
|
Method Overview Based on the analysis of the iToF imaging process, we propose iToF-flow to model the variation caused by the 3D motion and alternation of measurement mode, and develop an iToF-flow-based depth extraction neural network for high frame rate depth estimation. Specifically, from a physics-inspired perspective, we decompose the variation of iToF measurements into cross-mode flow, which models the photometric variation and pixel shift among different modes, and the uni-mode flow, which models the photometric residuals caused by depth-wise motion of the same mode. As for the cross-mode flow, we observe the motion-insensitive local linear transformation between different modes of the measurements and propose the LLT-based cross-mode transfer module (LCTM). As for uni-mode flow, we derive the depth-dependent photometric residual formulation and propose the uni-mode photometric compensation module (UPCM). With the end-to-end processing, the 3D motion is separated into the 2D plane of optical flow due to space shift and luminance residuals due to depth-wise motion, which can be extracted sequentially and separately. Local Linear Transformation: The challenging aspect of information propagation lies in accurately aligning the 2D motion flow between two modes at different times, known as cross-mode flow estimation. However, the photometric inconsistency introduced by the heterogeneous phase shift at different times degrades the performance of optical flow estimation methods. Thus we propose a motion-insensitive local linear transfer model that could formulate the mapping between different modes. Briefly, using LLT map we can generate photometrically consistent measurements at different moments for optical flow estimation. As shown in the figure below, the LLT robustness to motion edges is proven. Local area in (b), (c), (e) and (f) is marked with red box in (a). 
Network Structure We decompose the iToF flow depth estimation network into two modules: the cross-mode transfer and uni-mode photometric correction modules. Building upon these two modules, we propose the iToF flow-based depth estimation neural network that accurately estimates depth of each moment in an end-to-end manner by propagating absent phase information from previous measurements to the target time and correcting depth-wise motion-induced photometric-intensity-bias with the uni-mode flow. As shown in the figure below, framework of the proposed network is composed of cross-mode transfer module and uni-mode correction module including (b) submodule LMM of LCTM, (c) submodule SPE of LCTM and (d) UPCM. 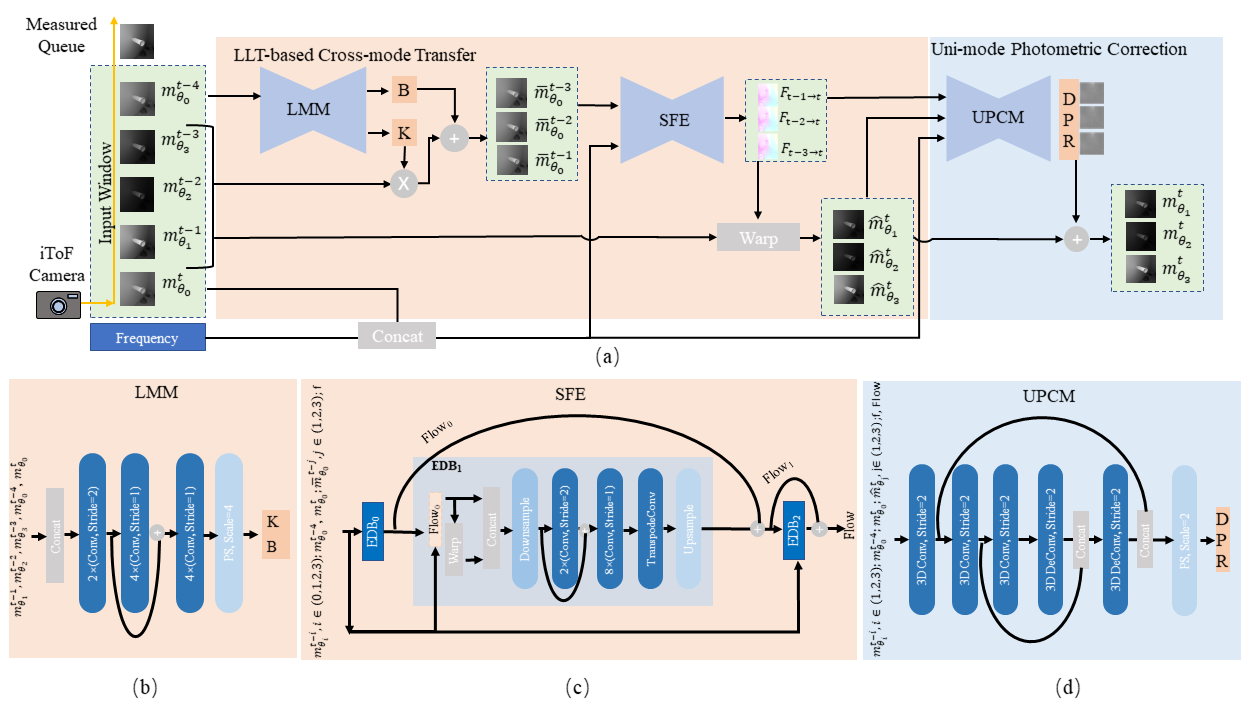
|
|
Experiments Visualization results for LLT As shown in the figure below,, the LMM-predicted linear mapping relationship between pixel intensities within the 16x16 sized region marked by the red box can all be formed by the slope k and intercept b from the center pixel. 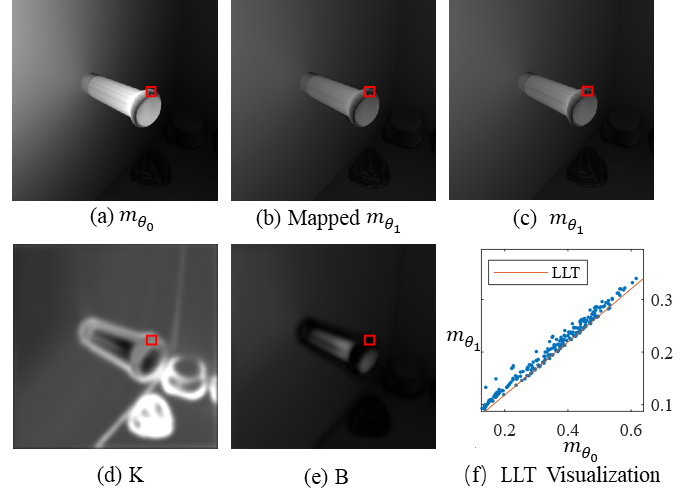 Comparisons with State-of-the-Art Methods The quantitative comparison results are shown below. Our method achieves the best performance in both photometric and depth reconstruction. Compared with the SOTA method FNN, the depth reconstruction error of our method is reduced by 37% and the runtime of our method is reduced to a quarter. 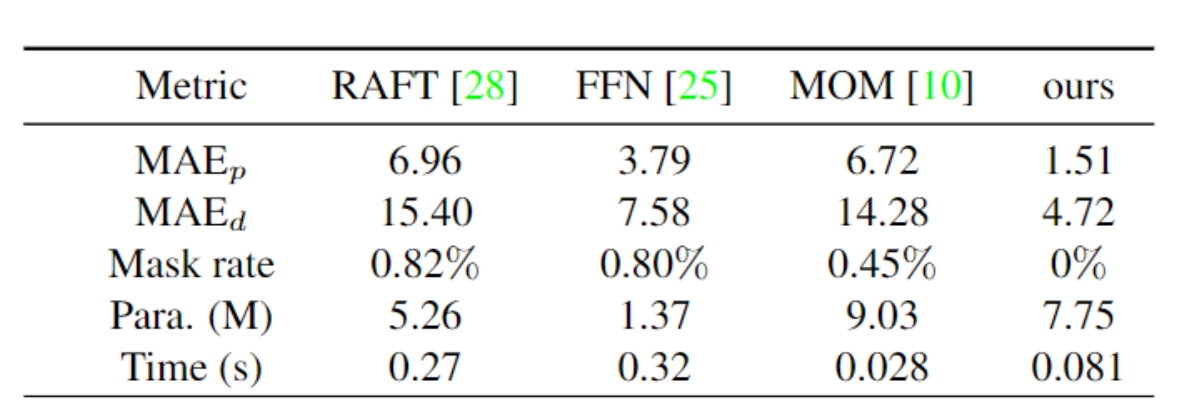
The visualization comparison is shown below. 
Additional Ablation Experiments We add 3 more experiments to demonstrate the effectiveness of iToF-flow,

For fair comparison, all these methods are retraining. Note that computing the CF-LLT with Eq. 2 in our paper need to split the image into local patches, introducing additional hyper-parameters like patch sizes. Here, we test a series of patch sizes (e.g., 8, 12, 16, 20), and present the best result with patch size 16. As shown, the best selected CF-LLT achieves slightly worse results than proposed method. Besides, the CNN-based LLT map exhibits greater smoothness than the CF-LLT map as depicted. The LMM-only can map the cross-mode intensity effectively, getting comparable or even better performance than FFN with much lower computational cost. However, it can not fully utilize the cross-mode correlation of the 4-mode measurements. The arctan2 operator used in depth estimation could amplify the slight errors in the retrieved photometric images, presenting relative lower photometric error and higher depth error. 
|
|
More Details |