Abstract
A unique bifocal compound eye visual system found in the now extinct trilobite, Dalmanitina
socialis, may enable them to be sensitive to the light-field information and simultaneously
perceive both close and distant objects in the environment. Here, inspired by the optical
structure of their eyes, we demonstrate a nanophotonic light-field camera incorporating a
spin-multiplexed bifocal metalens array capable of capturing high-resolution light-field images
over a record depth-of-field ranging from centimeter to kilometer scale, simultaneously
enabling macro and telephoto modes in a snapshot imaging. By leveraging a multi-scale
convolutional neural network-based reconstruction algorithm, optical aberrations induced by
the metalens are eliminated, thereby significantly relaxing the design and performance limitations
on metasurface optics. The elegant integration of nanophotonic technology with
computational photography achieved here is expected to aid development of future highperformance
imaging systems.
|
Method
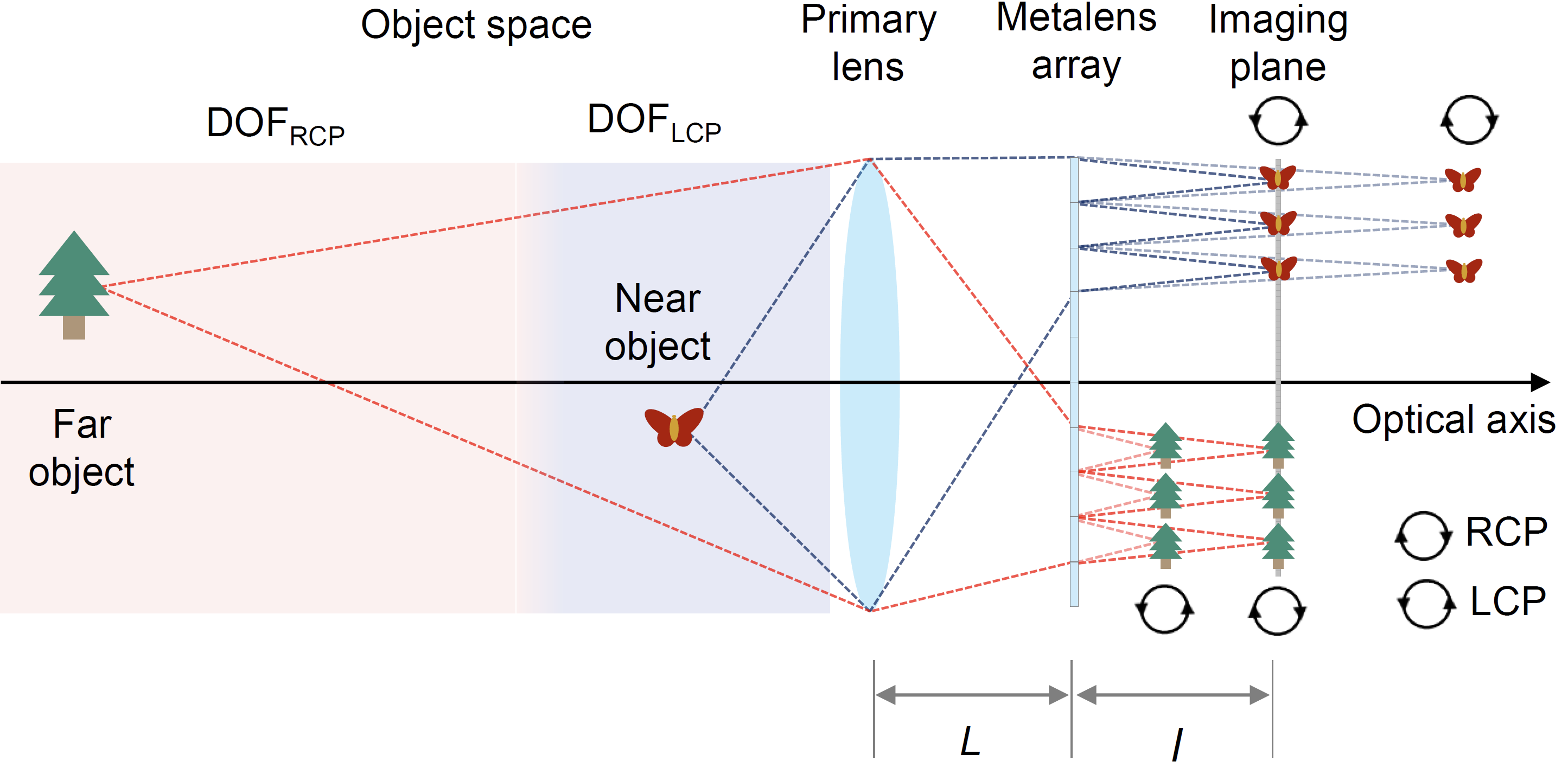
Schematic diagram
Schematic diagram of the working principle of the system with metalens array achieving spin-dependent bifocal light-field imaging.
The proposed method modulates circular polarization component of incident light, focuses scenes at different depths on the same image plane
and utilizes deep learning based reconstruction algorithms to remove aberrations.
Either the LCP component of close object or the RCP component of distant object could be focused well on the identical imaging plane.
The nominal distance between the primary lens and metalens array is L = 47.5 mm. The nominal distance between the imaging plane and metalens array is l = 0.83 mm.
The focal length and aperture size of the primary lens is F = 50mm and D = 6 mm, respectively.
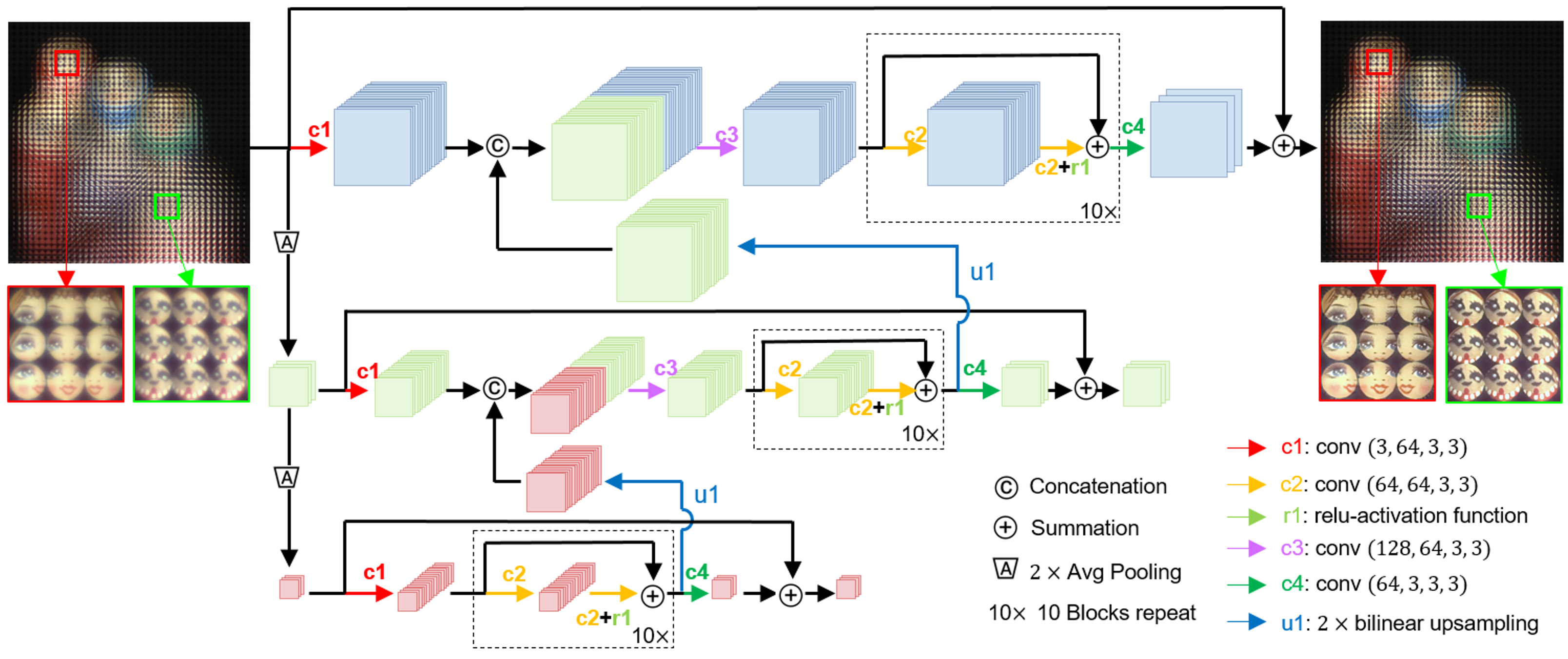
Network architecture:
Architecture of the distortion removal convolutional neural network. The network is
composed of 3 branches in different scales. Each branch of network is composed of residual blocks,
convolutional blocks, skip connections. The feature information of different scales are elegantly fused
together with convolutions and concatenations among different network branches.
Dataset
PSF capture and training-data generation.
In practice, we fix the camera and place a point light source at different positions from 0.03m to 5m to capture the PSFs and calibrate the PSF at infinity with a collimator.
The ground truth sharp images are generated from COCO dataset by randomly sampling 10,000 ground truth images.
We convolve the ground truth images with the calibrated PSFs to generate the distorted images and then cut them randomly into patches with pixel size of 224 × 224 to train the neural network.

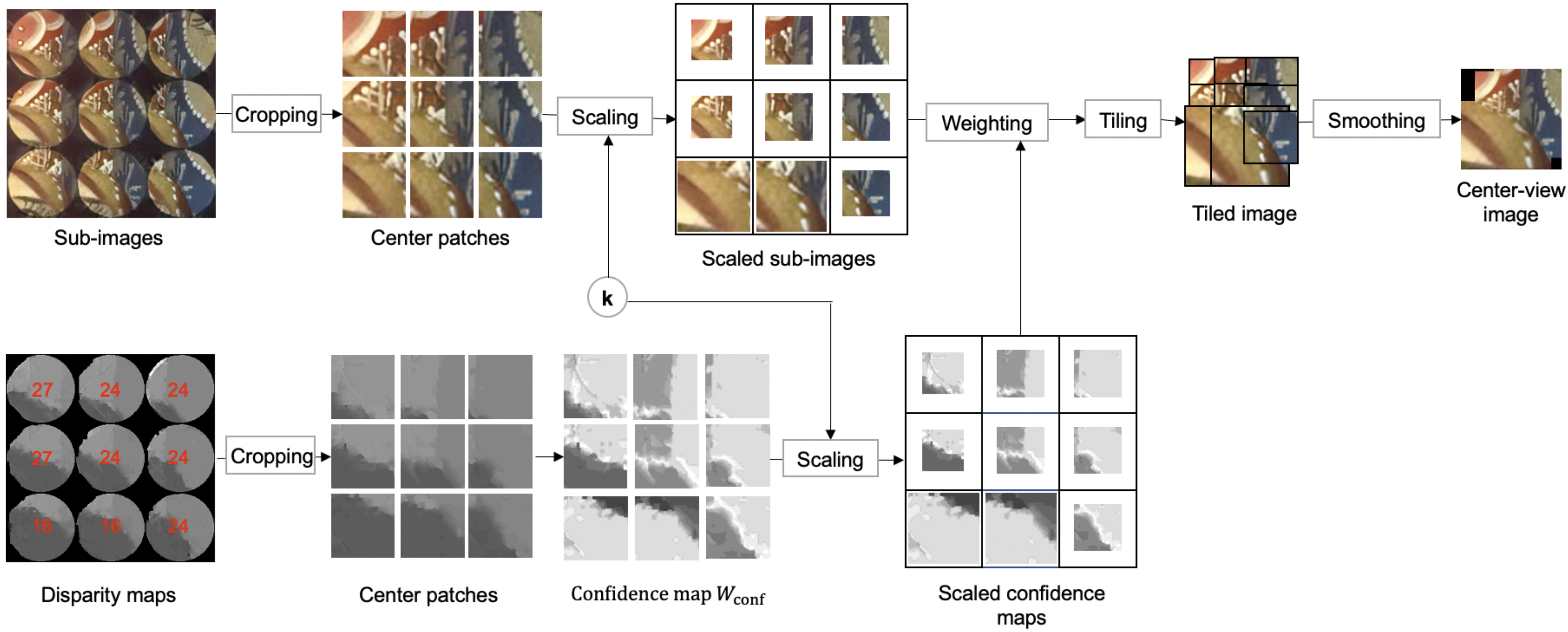
Rendering method
Pipeline illustration of the rendering method. Note that here we take a 3 × 3 sub-images
as example. Firstly, the center patch of each sub-image is extracted through cropping. Then the extracted
patches are rescaled depending on the dominant disparity of each sub-image. Thirdly, the rescaled
patches are weighted with the confidence maps calculated with the disparity map. Finally, the weighted
patches are tiled together into a rendered center-view image.
|
Experiments
Outdoor scenes
The overview of the imaging scene of Fig. 6 (in the main text). The scene is composed of
objects at different distances from the aperture of the primary lens, i.e., (a) 3 cm ‘NJU’ letters, (b) 0.35
m ruler, (c) 2 m color plate, (d) 10 m Nanjing University Logo, and (e) the outdoor scene.
Results
We select a scene covering an enormous depth from
3 cm to 1.7 km. A piece of glass patterned with opaque characters
“NJU” is placed at a depth of 3 cm away from the aperture of the
primary lens, which is used as the nearest object. A ruler, a color
plate, and a university logo are placed at the depth of 0.35 m, 2m,
and 10 m, respectively. The distance of white Chinese characters
on the rooftop and dormitory building are approximately 360m
and 480 m, respectively. The distance of the farthest highrise is
approximately 1.7 km. (a, b) Captured light-field subimages of the whole scene under natural light (a)
before and (b) after aberration correction. (c, d) Zoomed-in subimages of different objects corresponding to the marked ones shown in (a, b), respectively.
(e) Aberration-corrected all-in-focus image after rendering. The reconstructed NJU characters have been reasonably shifted and scaled for easy viewing.
Comparison
Captured images after removing the metalens array from the light-field imaging system.
The focusing plane is changed through adjusting the sensor position.
Since the ‘NJU’ letters on the glass plate are right at the front-end of the primary lens, it is impossible to focus at that plane through changing the position of the sensor.
As we can see from the graph, with the same f-number, it would take at least four shots with the main lens alone to clearly capture the scene within the same depth-of-field.

|
Bibtex
@article{Fan2022TrilobiteinspiredNN,
title={Trilobite-inspired neural nanophotonic light-field camera with extreme depth-of-field},
author={Qingbin Fan and Weizhu Xu and Xue-mei Hu and Wenqi Zhu and Tao Yue and Cheng Zhang and Feng Yan and Lu Chen and Henri J. Lezec and Yan-qing Lu and Amit Agrawal and Ting Xu},
journal={Nature Communications},
year={2022},
volume={13},
pages={16334-16343},
url={https://www.nature.com/articles/s41467-022-29568-y}
}
|
